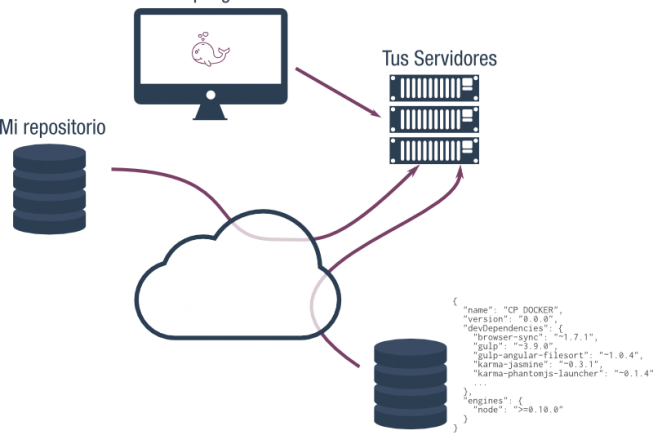
En este post voy a hablar de como organizar nuestra aplicación para que no
haya problemas a la hora de usar Docker. Estas instrucciones son parte de
un concepto más global llamado The 12 factor app cuyo contenido habla de
como organizar el código en entornos Saas.
De estos 12 puntos nos centraremos en los más importantes y aunque vamos a
explicar todo pensando en Docker se puede extrapolar a cualquier tipo de
sistema Saas.
Código base
El código de la aplicación tiene que ser totalmente ubícuo. Osea que podremos
acceder a el desde cualquier lugar y en cualquier momento.
Es muy recomendable que el código esté tenga un sistema de control de versiones
para que podamos obtener un punto concreto de nuestro desarrollo. Cualquier
sistema es valido: CVS, Git, Mercurial o SVN.
Otra característica importante es que el código se pueda descargar
automáticamente. Si tenemos nuestro código en Git y el código no es público se
necesita facilitar un usuario y una contraseña o una llave SSH. Por lo tanto
nuestro repositorio tiene que estar preparado para que ese proceso sea
automático.
>_ git clone -b master ssh://git@codecomposer.io/MyAPP.git /app/
Esto me parece más importante aun que el hecho de usar un repositorio, ya que
el objetivo es obtener el código automáticamente.
Dependencias
Para nuestras aplicaciones intentamos usar librerías o código de otros con el
fin de ahorrar tiempo y despreocuparnos de su testeo. El uso de librerías es
totalmente recomendable ya que estas suelen estar muy especializadas en su
propósito y seguro que alguien le ha dedicado más horas que nosotros a resolver
ese propósito.
El problema está en como integramos esto en nuestro código, primero y segundo
como ampliamos o modificamos esa librería. Por tanto lo primero que tendremos
que hacer a la hora de integrar un librería es saber si ésta cumple con el
primer concepto Código base con lo que podremos acceder a el desde cualquier
sitio y de manera automática. Esto nos va a permitir no incluir la librería en
nuestro repositorio y solamente vamos a registrarla en un fichero para que se
descargue por separado.
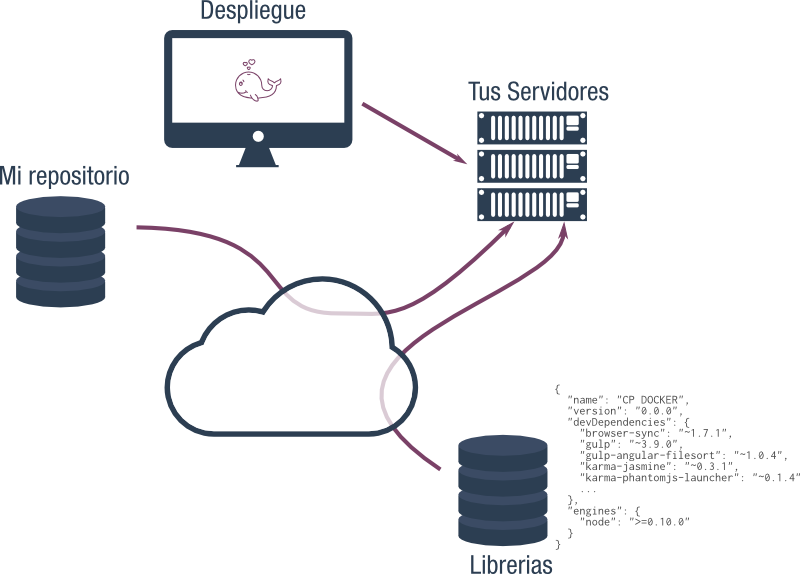
Esta forma de incluir una librería dependerá del lenguaje de programación y del
framework que usemos. Por ejemplo, si usamos NodeJS y NPM se define en un
fichero package.json como este:
{
"name": "CP DOCKER",
"version": "0.0.0",
"devDependencies": {
"browser-sync": "~1.7.1",
"gulp": "~3.9.0",
"gulp-angular-filesort": "~1.0.4",
"karma-jasmine": "~0.3.1",
"karma-phantomjs-launcher": "~0.1.4"
...
},
"engines": {
"node": ">=0.10.0"
}
}
Si usamos Python pondremos las librerías en un fichero requeriments.txt o en
PHP en composer.json. Si la librería que vamos a usar no se puede descargar con estos sistemas, es
mejor buscar otra.
Otro punto por el que es posible que una librería tenga que ser descartada es
si ésta no tiene una forma de extenderla o adaptar su comportamiento sin
tener que modificar su código fuente. Con lo cual no vamos a modificar bajo
ningún concepto el código de las librerías, de esta manera vamos a poder
separarlas de nuestro código y acoplarlas a voluntad.
Configuraciones
Este es uno de los puntos que personalmente más ha costado aplicar en los desarrollos. Antes de la aparición de los
Saas y de los Paas nos podíamos sentir muy orgullosos si conseguíamos
que nuestra aplicación no tuviese ningún parámetro de configuración dentro del
propio código. Tener todo en un fichero de configuración donde se podía cambiar
el password del usuario de la base de datos o el servidor SMTP que envía los
correos era un logro.
Ahora con estos servicios y con el objetivo de hacer nuestro código más
flexible y escalable se recomienda usar variables de entorno.
Una variable de entorno en linux se define de la siguiente manera:
>_ export REDIS_DB=app75
Una vez definido esta variable nuestro código la debe de usar. Por ejemplo con
Python:
import os
class Constants:
REDIS_HOST = os.environ['REDIS_HOST']
REDIS_PORT = os.environ['REDIS_PORT']
REDIS_PASS = os.environ['REDIS_PASS']
REDIS_DB = os.environ['REDIS_DB']
¿Y qué ganamos con usar variables de entorno? Pues, flexibilidad. Si ahora
desplegamos nuestra aplicación con Docker vamos a definir esas variables en
la propia definición de la máquina y meternos en el código para nada. Con lo
cual todo va seguir siendo automático.
>_ #Levantamos la maquina
>_ docker run -d -e REDIS_DB=app75 --entrypoint sh python:latest -c “pip install -r requeriments && python server.py”
La máquina se creará, instalará las librerías y arrancará el servicio usando
como base de datos de Redis app75.
Construir, desplegar, ejecutar
Se esta repitiendo mucho la palabra automático, pero es uno de los objetivos
del uso de contenedores Docker.
Para que nuestra aplicación se arranque automáticamente tenemos que aislar
estas etapas:

Construcción
Es la etapa inicial en la que preparamos el entorno sobre el que vamos a
ejecutar la aplicación. En nuestro caso, contenedores, prepararemos el o los
nuestros con los tipos que necesitemos. Siguiendo con el ejemplo de una
aplicación que nos va a servir como API REST usando Python y MongoDB. Tanto el
contenedor de Mongo como el de Python ya están construidos y simplemente con
ejecutarlos con las opciones adecuadas nos servirá.
Para pensar en un entorno bien construido vamos a incluir el código desde un
tercer contenedor.
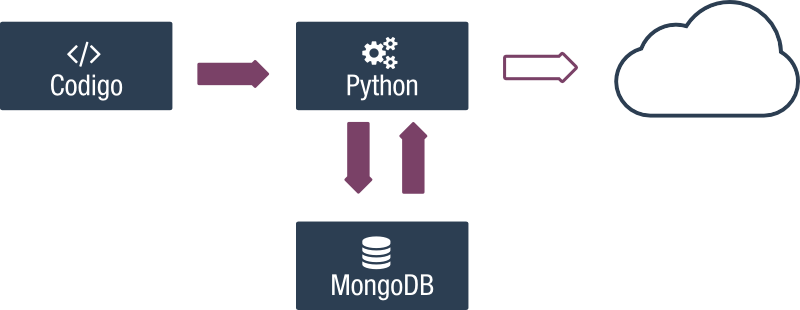
Este tercer contenedor descargará un repositorio de Bitbucket usando una
llave que previamente se ha autorizado en Bitbucket.
>_ IDRSA=$(grep "^--" -v ~/.ssh/id_rsa | paste -s -d "")
>_ docker run --name code -v /app -e IDRSA=$IDRSA \
-e REPO=dondocker/flask-app canonale/bitbucket
>_ docker run -d --name mongo mongodb
>_ docker run -d -e REDIS_DB=app75 --entrypoint sh \
--volumenes-from code -w /app/ --link mongo:mongodb \
python:latest -c “pip install -r requeriments && python server.py”
Con esto construiríamos el entorno.
Despliegue
Esta etapa prepara todas las librerías, descarga código necesario, crea las
bases de datos, en definitiva inicializa el entorno.
En el caso concreto de Docker todo esto se realiza en los entrypoint de
los contenedor. En entrypoint de un contenedor es el ejecutor del comando por
defecto que si no se define nada es sh. Este comando en una shell y
nosotros podemos definir nuestra propia shell. Hablamos de algo muy
sencillo. Imaginemos que nuestra maquina tiene que crear un par de carpetas
para guardar logs y descargar librerías antes de ejecutarse. Pues creamos
nuestra shell para tal fin_:
#!/bin/bash
# /entrypoint.sh
# Vamos a firenciar entre lo que hacemos con el comando principal y el resto
if [ “$1” = “comando__principal”]; then
mkdir -p /app/logs
pip install -r requeriments.txt
fi
exec “$@”
Esta shell va a instalar las librerías y crear la carpeta logs se ejecuta el
“comando_principal”.
Esto nos permite desplegar todas las ordenes que necesitamos para acomodarnos
el entorno y que al ejecutar la aplicación todo funcione y de manera
automática.
Esta “shell” es el principal motivo por el que vamos a necesitar modificar las
imágenes que ya están preparadas.
⚠ Importante: entrypoint.sh tiene que tener permisos de ejecución
Ejecución
Esta etapa con Docker ya la tenemos resuelta con el comando por defecto y
el entrypoint. Por lo tanto, con definir el contenedor de esta manera es
suficiente:
>_ docker run -d -e REDIS_DB=app75 --entrypoint /app/entrypoint.sh \
--volumenes-from code -w /app/ --link mongo:mongodb \
python:latest python server.py
De esta forma tendremos la ejecución determinada.
Por último, hay un cuarto punto que no se habla en el 12factor pero es
importante y es que una vez montada nuestra aplicación tiene que ser capaz de
actualizarse sin perdida de datos y de manera automática.
Para que esto sea posible tenemos que tener aislados los datos de nuestros
usuarios del código de tal manera que si destruimos el contenedor código y lo
volvemos a crear los datos se mantengan.
Para la actualización existen 2 opciones:
– La que hemos comentado ya es que cada vez que queramos actualizar el código o
librerías eliminemos el contenedor y lo volvamos a construir.
– Una alternativa, aunque similar, es reiniciar los contenedores que queramos
actualizar, teniendo en cuenta que se va a ejecutar nuestro entrypoint y debe
de tener en cuenta esto.
Cualquiera de las dos es valida, por ejemplo Kubernetes para actualizar
elimina los contenedores. Incluso si quieres cambiar algún puerto.
Paridad en desarrollo y producción
Es importante que cuando pongamos nuestra app en producción no nos llevemos
sorpresas y que haya cosas que funcionan mal o sencillamente no funcionen.
Para evitar esto tenemos que tener en cuenta que el entorno de producción y el
de desarrollo sean lo más idénticos posible.
Con Docker podemos conseguir esta similitud sin muchos cambios. Vamos a ver
un caso practico: Una aplicación con PHP y Symfony que vamos a instalar
Xdebug para desarrollo pero no lo vamos a usar en producción dado que baja en
rendimiento de la app.
Gracias a la opción de etiquetar distintas versiones de un contenedor,
construiremos nuestro contenedor para ejecutar symfony que llamaremos
mi-simfony y a partir de esta instalaremos Xdebug y lo etiquetariamos
como mi-simfony:dev Por otro lado Symfony nos permite disponer de varios
entornos manteniendo toda la estructura.
Para ejecutar una orden de la consola de Symfony hay que pasarle el entorno:
>_ php app/console cache:clear --env=[prod|dev|test]
Si esto lo definimos en una variable de entorno como explicamos antes:
>_ export environment=prod
>_ php app/console cache:clear --env=$environment
Esta orden será igual, independientemente del entorno con lo cual nuestro
scripts podrán ser igual para producción o desarrollo.
>_ #despliegue desarrollo
>_ docker run -d -e environment=dev mi-symfony:dev
>_ #despliegue produccion
>_ docker run -d -e environment=prod mi-symfony
Estas son unas pequeñas pinceladas de como organizar una aplicación para usar
Docker. Dado que esto se puede aplicar a cualquier tipo de micro servicio
se puede usar con otros entornos como Herokku. Por otro lado el
12factorApp es más amplio y es recomendable echarle un vistazo.
Espero que se de utilidad y que te ayudo a modelar tus aplicaciones.
Comentarios recientes