
Una de las facetas más olvidadas dentro de los sistemas y las aplicaciones, al menos por mi parte, es el tratamiento de los logs. En mi experiencia ha sido muy común desarrollar aplicaciones sin tan siquiera repara en ese factor.
Es muy común que los frameworks o las librerías dispongan de soluciones más o menos potentes. Claro que si no piensas en esto y tu aplicación empieza a tener cierta envergadura la cosa se complica y te puedes pasar horas buscando en logs de gigas a ver por que a tu cliente x no le ha cobrado el servicio y.
En el caso de los contenedores Docker el problema puede ser el mismo o incluso peor, debido a que la filosofía del uso de los microservicios es atomizar cada recurso y eso conlleva que vas a tener muchas más fuentes de datos.
Como ya sabemos Docker tiene una orden para mostrarnos los logs por pantalla. Pero que pasa si tienes, digamos, 20 contenedores como revisar que ha pasado en un momento dado. Pues para ello tenemos lo que se conoce como loggin drivers. Con ello vamos a poder gestionar la forma en la que queremos administrar nuestros logs.
Básicamente se trata de poder usar algún sistema independiente de la máquina en la que se ejecuta el o los contenedores y poder filtrar rápidamente. Nativamente y en la versión actual Docker cuenta con muchos driver:
| Driver | Descripción | Tipo |
|---|---|---|
| none | Suprime la salida de mensajes por parte del contenedor | Básico |
| json-file | Este es por defecto y suele usar para desarrollo. No recomendado en producción | Básico |
| syslog | Usa el estandar syslog y puede enviar los datos por TCP | Sistema operativo |
| journald | Es un formato muy usado en linux que usa el jornalist del sistema | Sistema operativo |
| gelf | Utiliza el fomrato GELF y junto a Graylog y Logstash es una buena solución | Recolectores |
| fluentd | Fluentd es un sistema colector de datos os tremendamente especifico | Recolectores |
| awslogs | Usa el sistema de logs de Amazon CloudWatch | Nube |
| splunk | Sistema colector de ddatos que usa HTTP | Nube |
| etwlogs | Usado para máquinas windows | Sistema operativo |
| gcplogs | Usa el sistema de la nube de Google GCL | Nube |
La clasificación de los drivers no es muy exacta y en la página de docker no existe, es una interpretación. Dicho esto nos vamos a centrar en un tipo el recolector por la siguiente razón el resto o ya tienen un interfaz ya creado, como el caso de los sistemas de nube, o son demasiado sencillos como básicos.
Gestión de logs con Fluentd
Como avance el la tabla anterior FluentD es un sistema colector de datos muy eficiente. Aunque es una aplicación open source dispone de una versión de pago que ofrece una solución completa para la gestión total de los datos.
La función de FluentD es por un lado filtrar los logs, por otro generar un buffer para que el envío y recogida de datos tenga una cadencia continua y por último enrutar o enviar los datos.
Esto quiere decir que con FluentD no vamos a poder ni almacenar y buscar en los logs. Pero la buena noticia es que FluentD dispone de infinidad de plugins que nos permiten comunicar el envío de datos a otras herramientas como Elasticsearch o MongoDB que almacenan los logs y luego podemos buscar eventos.
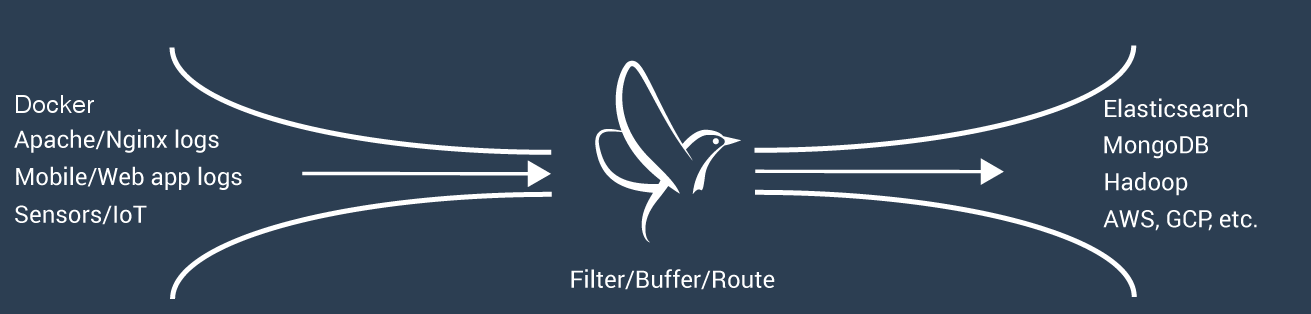
Por tanto la idea es utilizar el driver de FluentD y enviar los datos a un servidor de Elasticsearch que almacene todos los eventos que ocurran. Luego para mostrar la información de manera legible es posible que necesitemos un frontal web como Kibana o similar.
Además de la opción del driver, con Docker cada uno dispone de una opciones propias que para el caso de FluentD son:
- fluentd-address: especifica el servidor que va a recoger los datos, por defecto [localhost:24224]
- tag: Es la etiqueta por el que se conocerán los mensajes de este contenedor.
- fluentd-buffer-limit: especifica el tamaño máximo del buffer para el log, por defecto [8MB]
- fluentd-retry-wait: indica el retras inicial antes de enviar datos, por defecto. [1000ms]
- fluentd-max-retries: este es el número máximo de conexiones [1073741824]
- fluentd-async-connect: si se bloquea o no la conexión al arranque [false]
Arranque de los contenedores
Para indicarle a Docker que use este sistema de recopilación de datos deberíamos usar el siguiente comando.
>_ docker run -dti \ --log-driver=fluentd \ --log-opt fluentd-address=ip-fluentd:24224 \ --log-opt tag=”docker.{{.Name}}” \ alpine sh Con esto arrancaríamos una imagen alpine con el colector de fluentd. Pero necesitaros que ese colector esté arrancado para disponer de los datos. Para ello vamos a arrancar una imagen con FluentD con la siguiente configuración:
# test.conf
<source>
@type forward
</source>
<match docker.**>
@type stdout
</match>
Ahora arrancamos la máquina así
>_ docker run -d --name elasticsearch elasticsearch:2
>_ docker run -it --rm -p 24224:24224 -v $PWD/test.conf:/fluentd/etc/test.conf --link elastic:elasticsearch -e FLUENTD_CONF=test.conf fluent/fluentd:latest sh
$> fluent-gem install fluent-plugin-secure-forward
$> fluent-gem install fluent-plugin-elasticsearch
$> fluentd -c /fluentd/etc/$FLUENTD_CONF -p /fluentd/plugins $FLUENTD_OPT
En estos momentos ya está escuchando el acceso. Esta configuración de test simplemente escucha y reproduce el log del otro contenedor. Para comprobarlo solo tenemos que ejecutar cualquier acción que tenga resultado en pantalla en el contenedor a observar, por ejemplo:
# Contenedor a observar
>_ echo “Hola DonDocker”
# Fluentd Server
2016-10-28 18:34:37 +0000 docker.291db667a574: {"container_name":"/drunk_ardinghelli","source":"stdout","log":"/ # \u001b[6nhol\b\u001b[J\b\u001b[J\b\u001b[Jecho hola\b\b\b\bola\u001b[J\b\b\bla\u001b[J\b\ba\u001b[J\b\u001b[J\"hola do\b\u001b[J\b\u001b[JDonDocker\"\u001b[H\r/ # echo \"hola DonDocker\"\u001b[J\r","container_id":"291db667a574c21e6bb1b57a76e66a7d2bf2fd108a49852fb1415a655c94220d"}
2016-10-28 18:34:37 +0000 docker.291db667a574: {"container_name":"/drunk_ardinghelli","source":"stdout","log":"hola DonDocker\r","container_id":"291db667a574c21e6bb1b57a76e66a7d2bf2fd108a49852fb1415a655c94220d"}
Obviamente esto no tiene mucha utilidad, aunque solo con esta configuración podríamos centralizar para ver por pantalla los logs de todos los contenedores en funcionamiento.
Conectar con Elasticsearch
Ahora necesitamos guardar los logs en algún lugar. Podemos guardarlos todos en un único fichero pero esto dificulta el posterior filtrado y búsqueda de errores.
Por ello vamos a usar Elasticsearch como motor de almacenamiento. Para ello tenemos que cambiar la configuración del contenedor de FluentD
No he comentado nada sobre el funcionamiento interno de FluentD pero trabaja usando plugins que no están disponibles por defecto. Aquí está el listado de plugins que soporta FluentD
Para este caso vamos a necesitar el plugin de Elasticsearch y otro llamado record-reformer. Este segundo nos va a permitir reescribir los logs que recibimos, para añadir elementos o etiquetas.
La instalación es sencilla y solo tendremos que usar el comando fluentd-gem.
>_ fluent-gem install fluent-plugin-secure-forward
>_ fluent-gem install fluent-plugin-elasticsearch
Una vez instalados los plugins vamos a modificar la configuración para enviar los datos a Elasticsearch.
<source>
@type forward
</source>
<match *.*>
type record_reformer
tag elasticsearch
facility ${tag_parts[1]}
severity ${tag_parts[2]}
</match>
<match elasticsearch>
type copy
<store>
type stdout
</store>
<store>
type elasticsearch
logstash_format true
flush_interval 5s #debug
host elasticsearch
port 9200
</store>
</match>
Desgranando un poco la configuración vemos dos nuevos ajustes. El primero es una etiqueta <match > que va a tratar todos los datos de entrada y les va a añadir la etiqueta elasticsearch. A continuación volvemos a filtrar con <match > esta vez con la etiqueta elasticsearch que previamente hemos puesto. Ahora almacenamos el resultado en 2 sitios diferentes: el primero la salida por pantalla type stdout como el que teníamos antes y el segundo lo enviamos, ahora sí, a Elasticsearch. indicando la ip y el puerto.
Para el servidor de Elasticsearch podemos usar el contenedor oficial ya que no vamos a realizar ningún cambio sobre el.
>_ docker run -d --name elasticsearch elasticsearch:2
>_ docker run -it --rm -p 24224:24224 -v $PWD/test.conf:/fluentd/etc/test.conf --link elastic:elasticsearch -e FLUENTD_CONF=test.conf fluent/fluentd:latest sh
$> fluent-gem install fluent-plugin-secure-forward
$> fluent-gem install fluent-plugin-elasticsearch
$> fluentd -c /fluentd/etc/$FLUENTD_CONF -p /fluentd/plugins $FLUENTD_OPT
Ya tenemos el sistema en funcionamiento. Ahora podemos crear un contenedor y verificar que funciona.
>_ docker run -dti \
--log-driver=fluentd \
alpine sh
$> echo “HOLA ESTOY AQUI”
$> echo “HOLA ESTOY AQUI”
$> echo “HASTA LUEGO”
Si vamos a la máquina de FluentD veremos por pantalla estos mensajes como mostramos antes. Para verificar que Elasticsearch está almacenado los mensajes que FluentD le manda tendremos que hacer una petición directa de esta forma:
>_ curl -XGET ‘http://IP-ELASTIC:9200/_all/_search
{
"took": 3,
"timed_out": false,
...
"hits": {
"total": 20,
"max_score": 1,
"hits": [
{
"_index": "logstash-2016.10.29",
"_type": "fluentd",
"_id": "AVgRMXhTf8yIYMtrE6Fr",
"_score": 1,
"_source": {
"container_id": "d052e7fb4712ba4db5726a8f20aff768b94e2d5ed4efb31baba9ef0ba6e75817",
"container_name": "/hungry_yonath",
"source": "stdout",
"log": "/ # \u001b[6n\r/ # echo \"HOLA SOY YO\"\u001b[J\r",
"facility": "d052e7fb4712",
"severity": "",
"@timestamp": "2016-10-29T16:06:40+00:00"
}
},
...
Vemos el texto que hemos introducido en el contenedor hungry_yonat. Pero está claro que usar curl para obtener los datos no es una manera practica de entender que está pasando. La solución es usar un sistema de visualización gráfica de datos.
Existen diferentes alternativas para visualización de datos con gráficos, está Grafana por ejemplo o Kibana que está muy optimizado para el uso junto a Elasticsearch.
El sistema que mejor entiende a Elasticsearch es Kibana.
Integración de Kibana
Para esta prueba podemos usar el contenedor oficial de Kibana. Para ello solo hace falta arrancarlo enlazándolo con Elasticsearch.
>_ docker run --link elasticsearch:elasticsearch -p 5601:5601 --name kibana --rm kibana:latest
Si todo está correcto podremos ir al navegador y ver la aplicación.
No voy a explicar en profundidad como funciona o que cosas se pueden hacer con Kibana (tampoco es que sepa mucho). Lo que si voy a mostrar es como podemos ver gráficos y obtener una mínima interpretación.
El primer filtro que va a usar Kibana a la hora de buscar va ser el indice y cuando entremos al programa no va a pedir cual va a ser ese indice. Si nos fijamos en los datos que muestra Elasticsearch vemos que hay un campo llamado _index.
"max_score": 1,
"hits": [
{
"_index": "logstash-2016.10.29",
"_type": "fluentd",
"_id": "AVgRMXhTf8yIYMtrE6Fr",
Ese es el campo que va a filtrar y el formato será logstash-YYYY.MM.DD En el caso de esta instalación yo no he tenido que completar este indice pero en instalaciones manuales si he tenido que crear este indice.
Una vez que hemos definido el indice podemos ir a la pantalla Discover. En como una especie de tabla con todos los registros del indice pero ubicados temporalmente.
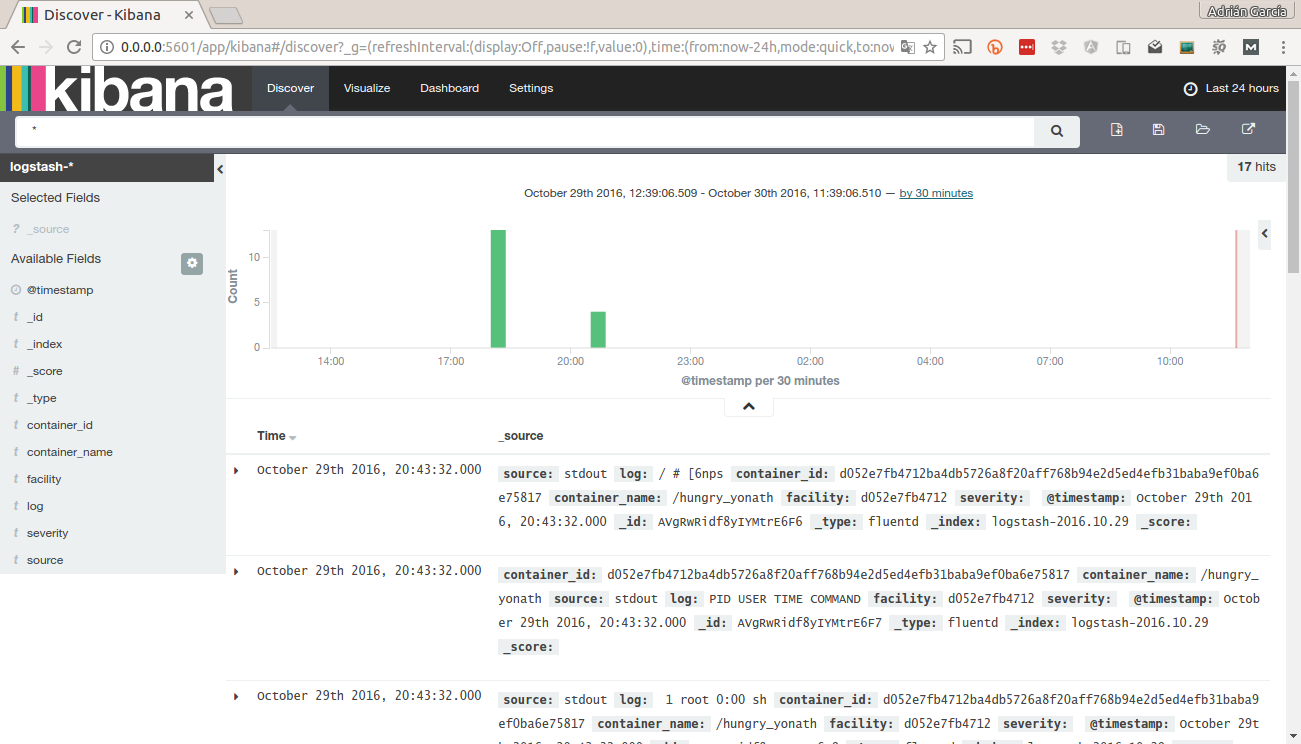
Esta pantalla es algo así como ver los logs de manera gráfica. También se pueden filtrar por términos o ajustar el periodo de tiempo.
Vamos a dar un paso más allá y vamos a un gráfico que nos ayude a interpretar un poco mejor posibles problemas o casuísticas. Dado que la información que estamos almacenado es muy sencilla, a parte de la fecha y el nombre del contenedor solo nos queda un campo por el que poder filtrar que es de log. Entonce vamos a crear un gráfico de sectores para ver cuales son las palabras más repetidas en la shell del contenedor.
Para ello, vamos a la parte de Visualice, una vez que aparezca el listado de tipos de gráficos seleccionamos Pie chart
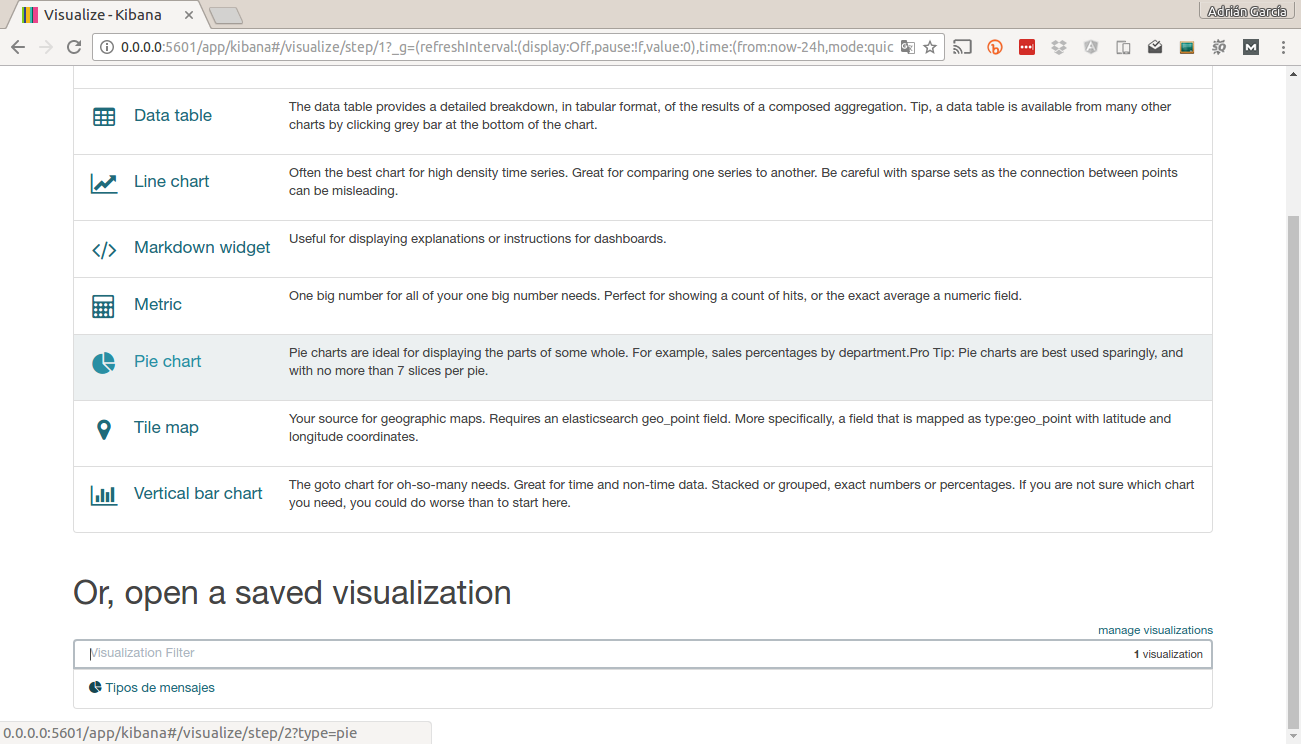
Luego indicamos una nueva búsqueda. Nos aparecerá un gráfico sin ninguna segmentación. Para completarlo pinchermos en Split slices a continuación como vamos a segmentar por uno de los campos tenemos que seleccionar Terms y en Field seleccionamos el campo por el que vamos a segmentar, en este caso log. Por último le damos al botón verde (play) y veremos el siguiente gráfico:
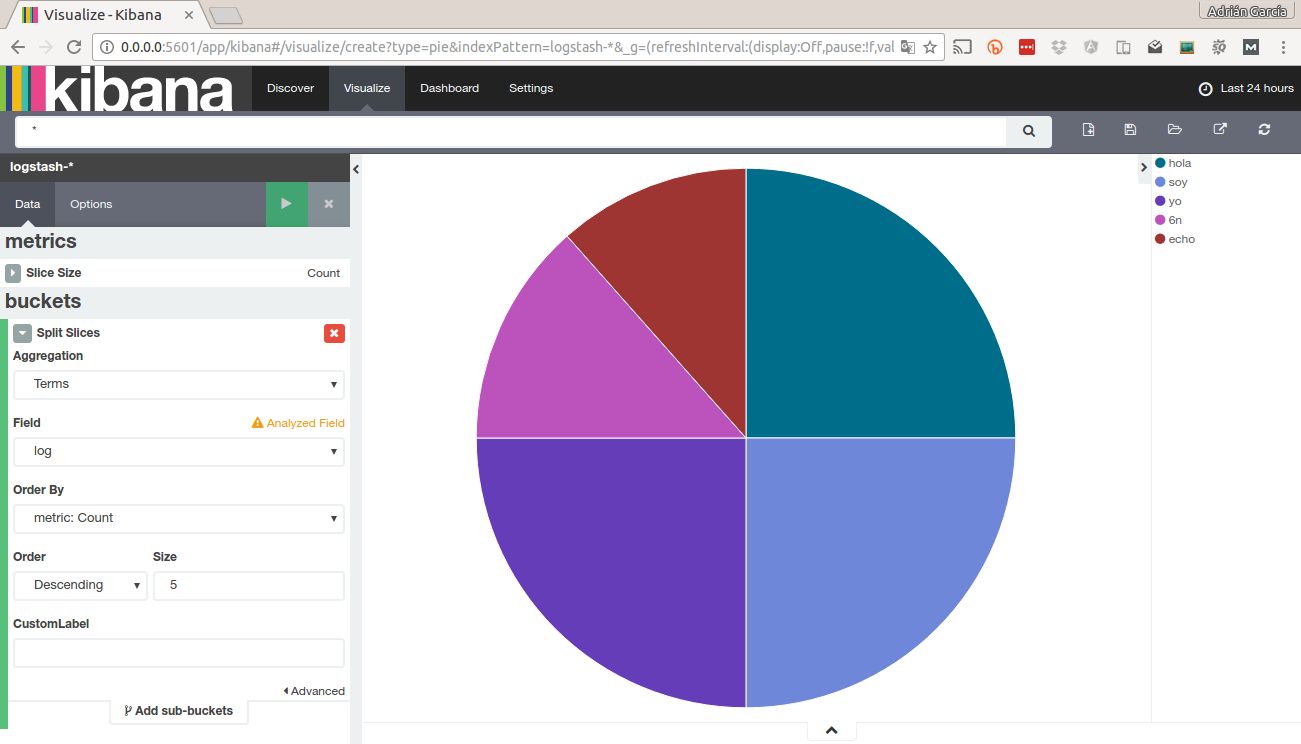
Este gráfico nos muestra la naturaleza de los mensajes de la shell y no tiene ninguna utilidad. Pero si los contenedores fueran servidores apache podríamos hacer gráficos de porcentajes de errores, peticiones por minuto, errores recurrentes o bytes enviados.
Como veis las posibilidades son enormes y todo esto facilita mucho la toma de decisiones a corto y a largo plazo. Y como siempre un gráfico o dibujo es más fácil de entender que una tabla con cifras. Por tanto os animo a usar los drivers que tienen Docker para unificar los logs y llevarlos a otro servidor aislado del resto para evitar problemas.
Gracias por leer el contenido y espero que sea de utilidad. Si es así compártelo en tus redes sociales.
Un saludo.
Comentarios recientes